From Guardrails to Control Plane: The Next Phase of AI Agent Governance
Enterprise teams do not need another AI security console. They need a control plane that governs actions at runtime, plugs into existing systems, and produces evidence that holds up during incidents and audits.

Nyah Check
May 6, 2026 · 11 min read

A year ago, most conversations about agent security started and ended with one question: "Can you block bad tool calls?"
Fair question. It still matters.
But if you are running real production workflows, that question is now table stakes. The harder questions come right after:
- Will this fit our existing security stack, or create another operational island?
- Can we roll this out without slowing engineers to a crawl?
- When something goes wrong, can we explain exactly what happened in one clear chain?
Over the last few weeks, that shift has become obvious in almost every enterprise conversation we have had. People are done buying another console.
They are looking for a runtime control plane.
The shift we are seeing in the field
The early market asked for a product demo. Current buyers ask for operating evidence. In practical terms, the center of gravity moved from feature lists to these diligence questions:
- Where do you sit in the action path?
- What happens on timeout, denial, or partial outage?
- How do we route approvals into what we already use?
- Can we retrieve decision evidence fast enough for incident response and audit?
- Who owns policy tuning across Security, GRC, and Platform?
None of this is flashy. All of it determines whether a pilot becomes production.
Why approval alone is not governance
Most teams already have solid foundations:
- identity and access controls,
- secrets and credential management,
- SIEM and incident tooling,
- existing change and risk workflows.
Those controls answer "who can access what." They do not answer the runtime question that causes pain later:
"Should this action execute right now, in this context?"
That gap is exactly where teams get stuck in post-incident review. They can show credentials were valid. They can show logs were collected. But they still cannot answer the question leadership cares about: "Why did this specific action run?"
How our thinking evolved
When we started Thoth, we focused on runtime guardrails. That was the right first move. Then production usage forced us to evolve.
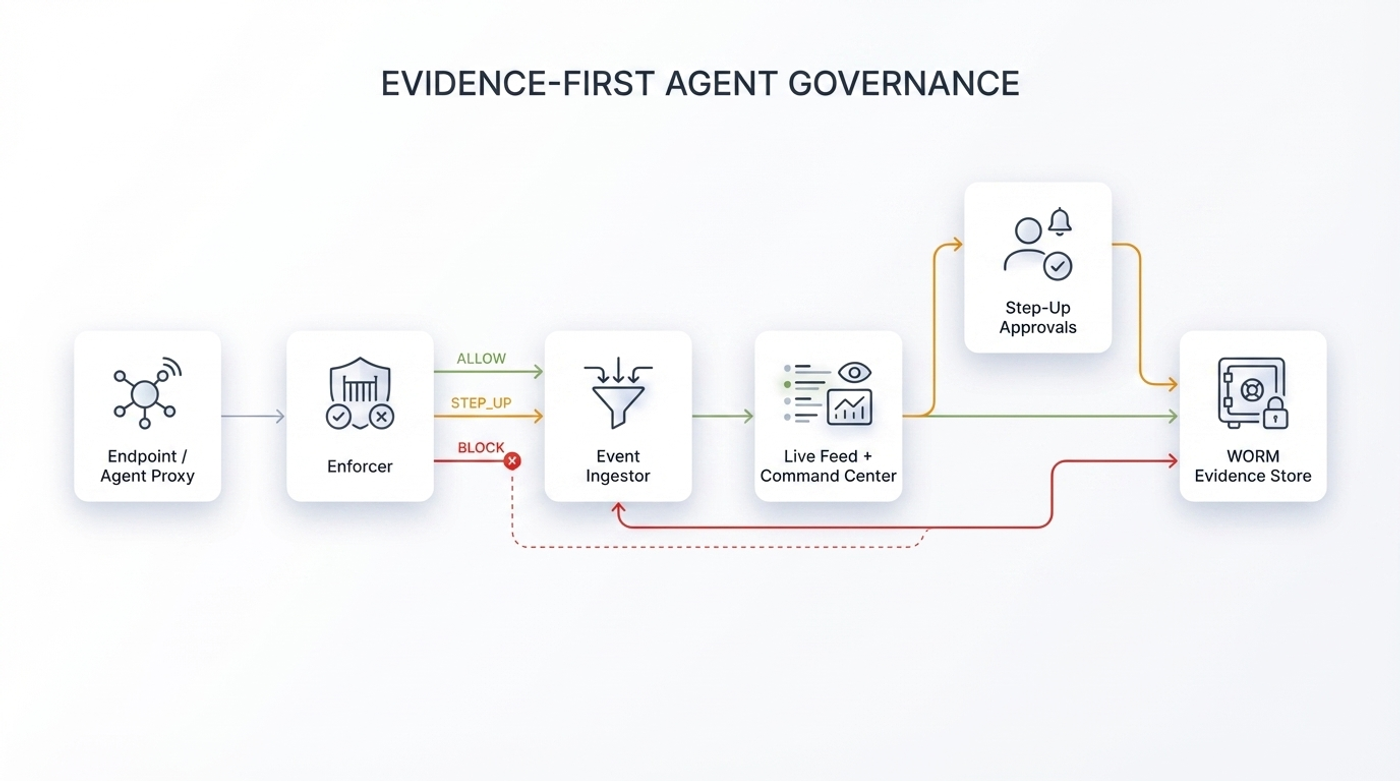
Phase 1: Guardrails
We started with direct runtime outcomes:
- `ALLOW`
- `STEP_UP`
- `BLOCK`
This gave teams a way to prevent obvious out-of-scope actions.
Phase 2: Evidence-first governance
Prevention helped, but incident and audit needs were still under-served. So we expanded the model to retain context around every decision, including rejected and escalated actions:
- endpoint and agent identity,
- user and session context,
- tool and argument context,
- policy rationale,
- approval lifecycle history.
That gave teams usable records instead of disconnected event fragments.
Phase 3: Integration-first control plane
Then came the reality of enterprise operations:
If runtime governance does not plug into existing systems, teams will not trust it at scale. So the current focus is operational fit:
- headless APIs for enforcement and evidence readback,
- routing step-up into channels teams already run,
- event export to SIEM/IR workflows,
- deployment options that satisfy boundary and key custody requirements.
This is the difference between a feature and an operating system for governance.
What a runtime control plane actually needs
A lot of teams hear "control plane" and think it means a bigger UI.
That is not the point. A runtime control plane has six working parts:
1. Execution interception: Intercepts a candidate action before irreversible execution.
2. Decision engine: Evaluates policy plus runtime context and returns `ALLOW`, `STEP_UP`, or `BLOCK`.
3. Approval lifecycle: Holds high-risk actions safely, tracks reviewer decisions, and resolves final disposition.
4. Evidence pipeline: Writes context and rationale into an evidence trail teams can query during incidents.
5. Integration layer: Pushes outcomes to SIEM, IAM/PAM, ticketing, and alerting systems already in use.
6. Policy feedback loop: Uses real incidents and reviewer outcomes to tune policy quality over time.
If one of these is weak, governance quality degrades fast.
What technical teams evaluate in diligence
In deep technical sessions, the same topics come up repeatedly.
Decision quality
- Which inputs are evaluated at runtime?
- Which rule or threshold drove the final decision?
- How do you tune noise down without opening risk back up?
Step-up integrity
- How is an action held while waiting for approval?
- What happens on timeout?
- How do you prove the final action maps back to the original request?
Evidence usability
- Do you retain escalated and blocked attempts, or only allowed traffic?
- Can responders reconstruct sequence quickly, without detective work?
- Can the same records serve both engineering triage and formal audit asks?
Integration friction
- Can this plug into existing SOC runbooks without a redesign project?
- Can policy changes follow existing change-control discipline?
- Can deployment match our internal trust boundaries?
Strong answers here usually predict a successful rollout.
Rollout model that avoids production shock
The fastest way to lose trust is to jump straight to hard blocking.
What works better is boring and disciplined:
Stage 0: scope the first workflows
- pick high-risk, high-consequence action classes,
- define approval responsibilities,
- define fallback behavior before rollout.
Stage 1: observe
- collect runtime behavior with zero blocking,
- validate metadata and integration paths,
- identify policy candidates from actual traffic.
Stage 2: progressive controls
- escalate only on stronger signals,
- measure operator load and approval latency,
- tune rules and exception handling.
Stage 3: targeted hard enforcement
- block clear violations in scoped workflows,
- keep broader surfaces in progressive mode,
- widen only when signal quality is stable.
Stage 4: continuous governance
- fold incidents back into policy updates,
- review drift and exception aging,
- run regular evidence-readiness checks.
This pattern lets teams keep delivery velocity while maturing controls.
Scorecard: metrics that tell the truth
Without a shared scorecard, control quality becomes subjective.
Executive metrics
1. Time to first confidently enforced workflow.
2. Reduction in unmanaged high-risk action attempts.
3. Evidence readiness for incident and audit review.
4. Adoption across Security, GRC, Platform, and AI Engineering.
Technical metrics
1. Mean step-up approval latency.
2. False-positive rate in protected workflows.
3. Policy coverage of priority action classes.
4. Time to pull complete evidence package during an incident.
5. Reliability of integration into SIEM and response flows.
Governance metrics
1. Exception aging and closure rate.
2. Policy drift over 30/60/90 days.
3. Manual override ratio versus deterministic outcomes.
4. Escalation usefulness rate (signal vs noise).
If these numbers are not tracked, teams usually overestimate their control maturity.
Failure patterns we keep seeing
Most stalled programs fail for predictable reasons:
1. Blocking too early. Teams enforce hard controls before they understand baseline behavior.
2. UI-first implementation. Work focuses on dashboards instead of operational integration.
3. Thin evidence model. Teams keep allowed events but lose rejected and escalation context.
4. Blurred ownership. No clear owner for policy tuning, exceptions, and lifecycle decisions.
5. Broken feedback loop. Humans approve actions, but those outcomes never improve future policy.
None of these are novel. All of them are fixable.
Deployment boundary questions are now first-class
This part is no longer "later-stage legal work." Buyers ask it early.
Teams want explicit answers on:
- customer managed versus hosted boundary,
- key custody and access model,
- telemetry retention and access controls,
- tenant isolation expectations,
- behavior during control path degradation.
If those boundaries stay fuzzy, enterprise programs slow down fast.
A practical 30/60/90-day path
Days 0-30
- instrument priority workflows,
- run observe mode,
- validate event schema and evidence quality,
- complete SIEM and incident-path integration checks.
Days 31-60
- enable progressive controls for scoped workflows,
- run a staffed step-up responder rotation,
- tune false positives weekly,
- begin hard enforcement for clear violations.
Days 61-90
- expand enforcement perimeter based on measured stability,
- run incident drills with evidence retrieval,
- publish a cross-functional governance scorecard,
- set policy lifecycle cadence.
By day 90, teams should be operating a repeatable governance program, not an experiment.
What mature operations can answer quickly
When a program is working, teams can answer these in minutes:
- Which high-risk actions were attempted this week?
- Which were allowed, escalated, or blocked, and why?
- Who approved which step-up actions under what context?
- Which policy changes came from incident or escalation patterns?
- How quickly can we produce a defensible evidence package?
That is the difference between "we have controls" and "we can run this safely at scale."
## Closing
Agent security is moving from point guardrails to runtime control planes.
That is the direction we have been building toward with Thoth:
- action-time governance,
- integration into the systems teams already run,
- evidence that holds up when scrutiny gets real.
The next phase of enterprise AI is not just deployment. It is operations with accountability.
Get practical updates on AI agent security and governance.
Twice monthly notes on incidents, controls, and implementation lessons from real enterprise deployments.

